FAX OCRに向いているAIモデルはどれか?
実帳票で比較した選定基準
FAX OCRの精度を上げようとすると、まず「どのAIモデルを使うか」に目が向きます。最新モデルを使えば全部よくなるように見えますが、実際のFAX帳票ではそう単純ではありません。
SP-FAXでは、匿名化した社内検証用帳票で、軽量モデル、標準モデル、高精度モデル、最新モデルを継続的に比較しています。見えてきたのは、単一モデルで全帳票を処理するより、帳票の難しさと処理段階でモデルを切り替える方が安定するということです。
※ 本記事では顧客名、帳票ファイル名、住所、電話番号、商品名などの固有情報を公開していません。検証結果は公開用に抽象化しています。
比較で見た4つの観点
FAX OCRでは、文字認識の強さだけでなく、業務データとして安定して出せるかが重要です。SP-FAXの検証では、主に次の4点を見ています。
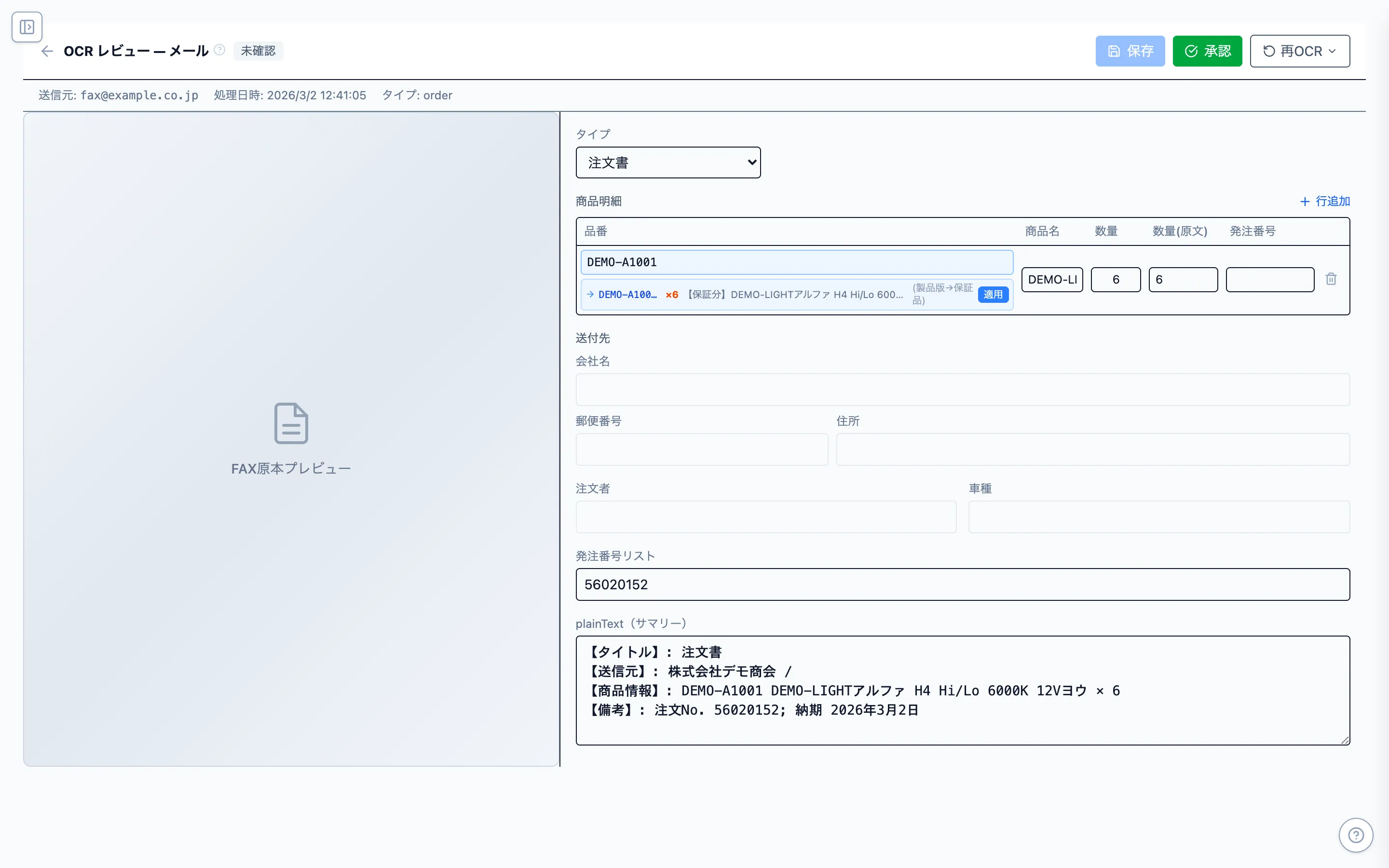
1. 明細の安定性
商品名、数量、単位、行番号が過不足なく出るか。拾いすぎも実務上はエラーになります。
2. 周辺情報の抽出力
店舗名、納品先、住所、TEL、備考など、明細以外の情報をどこまで拾えるか。
3. 長い帳票への耐性
複数ページや明細量の多い帳票で、途中で出力が切れずに完了するか。
4. 処理コストとのバランス
高精度でも全件に使うと価格に跳ね返るため、標準利用できるかを分けて判断します。
モデル別の向き不向き
| モデル分類 | 向いている用途 | 注意点 |
|---|---|---|
| 軽量モデル | 帳票種別判定、ページ役割の判定、低リスク帳票の一次処理 | 長い帳票や明細量の多い帳票では出力不足が起きやすい |
| 標準モデル | 通常の注文書、請求書、出荷指示書の本処理 | 難帳票では住所・TEL・備考の補完が必要になる |
| 高精度モデル | 手書き混在、低画質、住所/TEL抽出、再OCR | 情報を拾いすぎることがあり、明細の過抽出を検知する必要がある |
| 最新モデル | 難帳票のスポット検証、新しい補正ロジックの材料 | 品質が上がる部分と不安定になる部分を分けて評価する必要がある |
軽量モデルは「本処理」より「前処理」に向く
軽量モデルは速く、コストを抑えやすい一方で、複数ページや行数の多い帳票では出力が足りなくなることがあります。特にFAX OCRでは、1ページ目だけでなく、2ページ目以降の明細や備考まで構造化する必要があります。
そのためSP-FAXでは、軽量モデルをいきなり本処理の主役にするより、帳票種別の判定、ページ分割後の役割判定、低リスクページの一次スキャンに使う方が現実的だと見ています。
標準モデルを軸にする理由
実務で大事なのは、最高点を出すことではなく、毎日届く帳票を安定して処理できることです。SP-FAXの検証では、標準モデルは明細の安定性と処理コストのバランスがよく、標準処理の軸にしやすい結果でした。
もちろん、すべての帳票で完璧ではありません。住所・TEL・自由記述欄・手書き混在のような難所は残ります。だからこそ、標準モデルをベースにしつつ、Guardで危険なページを見つけ、必要な箇所だけ高精度モデルへ回す設計にしています。
高精度モデルは「全部に使う」より「難所に使う」
高精度モデルは、住所・TELや帳票の周辺情報を拾う力が強く、難しい帳票では明確に価値があります。一方で、情報を広く拾うぶん、明細を余計に増やしたり、本来商品名に入れたくない文字を混ぜたりするケースもあります。
この性質は、Gemini 3.5 Flashの検証メモでも確認しています。高精度モデルは強いですが、全件標準にするより、再OCR・補完・危険判定後のフォールバックに使う方が価格と品質の両方を守れます。
SP-FAXのモデル切替イメージ
- 軽量モデルで帳票種別とページ役割を判定する
- 通常ページは標準モデルで構造化する
- 行数、店コード、数量、住所/TELの不足をGuardで確認する
- 危険なページだけ高精度モデルで再OCRする
- 差分をレビュー画面に出し、人が直した内容を辞書・マスタ補正へ反映する
この切替設計なら、全件を高価な処理に寄せずに、難しい帳票だけ精度を上げられます。FAX OCRを業務に入れるなら、モデル単体の比較よりも、こうした運用設計まで含めて見る必要があります。
関連記事
自社帳票でAI OCRを検証できます
SP-FAX OCRは登録後50枚無料。モデル選定だけでなく、確認画面・辞書・外部連携まで試せます。
50枚無料で試す